【编程随想】博弈论入门教程——从基本概念到具体案例 |  |
| Posted: 18 Nov 2020 08:10 AM PST 又静默了好几天。最近几个晚上,俺在准备这篇教程,没上线回复评论。抱歉 :( 先提醒一下:今天这篇又是信息量比较大的博文。喜欢学习的同学,请慢慢看,不要着急 :) ★引子最近3年,俺写过好几篇博文,是与博弈论密切相关的。比如2017年的朝核危机,俺写了2篇,专门谈"北韩&美国"的博弈策略。 近期恰逢美国大选,很多读者在博客评论区讨论相关的话题。有时候俺也参与讨论,并多次提及"博弈论"的相关概念。考虑到很多读者(即使是理工科的读者)也非常缺乏这方面的基础知识,今天发一篇博弈论的基础教程,算是扫盲。 ★概述"博弈论"洋文称之为"game theory"。目前它是经济学的一个分支(所以俺网盘上分享的博弈论书籍,都放在【经济学 / 博弈论】这个分类目录下)。 该理论专门研究多个独立个体之间的竞争行为(对抗行为)。在某些中文书籍里面,它又被称作"对策论 or 赛局理论"。 ★"博弈论"的起源在这篇扫盲教程的开头,咱们来闲聊一下"博弈论"的发展史。 要聊这个话题,约翰·冯·诺伊曼(John von Neumann)当然是个无法绕过的人物。  (约翰·冯·诺伊曼) 这家伙是个【超级跨界牛人】,即使用这么夸张的称呼,依然不足以体现此人的牛逼之处——他同时在"数学、物理学、经济学、计算机"等多个领域作出了划时代的贡献,并留下一大堆以他命名的东东,比如程序员应该都听说过"冯诺依曼体系",比如数学领域有"冯诺依曼代数、冯诺依曼遍历定理",理论物理领域有"冯诺依曼量子测量、冯诺依曼熵、冯诺依曼方程"。另外还有很多东东,虽没有以他命名,也是他先搞出来滴,比如:量子力学的公理化表述、希尔伯特第5问题、连续几何(其空间维数不是整数)、蒙特卡洛方法、归并排序算法...... 1944年,他与奥斯卡·摩根斯坦(Oskar Morgenstern)合作发表了《博弈论与经济行为》(洋文叫做"Theory of Games and Economic Behavior"),一举奠定博弈论体系的基础,所以他也被称作【博弈论之父】。 这个《博弈论与经济行为》一开始是以论文形式写成,长达1200页,基本上是冯·诺伊曼一个人的手笔。有些同学会纳闷了——那摩根斯坦凭啥当第二作者呀?这里面大致有2个原因: 其一,摩根斯坦本人非常看好"博弈领域的研究",他认为:该领域的研究可以为一切经济学理论建立正确的基础。当他结识了冯大牛之后,就一直劝说这只大牛写篇该领域的论文。 其二,当冯大牛完成上千页的论文之后,摩根斯坦为这篇论文补了一个非常有煽动性的"绪论",使得这篇论文一发表就在数学界&经济学界产生轰动效果。 所以,把摩根斯坦列为第二作者,也算说得过去。 另外,这本《博弈论与经济行为》的某些思想源自冯·诺伊曼在1928年发表的论文《On the Theory of Parlor Games》。因此有些学者认为1928年才是真正意义上的博弈论诞生之年。 插播一个八卦 摩根斯坦的博士生导师就是赫赫有名的路德维希·冯·米塞斯(俺的网盘上分享过他的好几本著作)。有一种说法是:米塞斯在20世纪初就已经意识到"博弈论对经济学的重要性",但他因为种种原因没能建立起博弈论的完整理论体系。米塞斯的这个想法影响了他带出来的博士生摩根斯坦。而摩根斯坦去美国做访问学者的时候,又影响了冯·诺伊曼。 上述这个说法的可信度有多高,俺不敢保证。但米塞斯具有很超前的预见性,这点是得到公认滴。举个例子—— 2年前(2018)俺写了那篇《为什么马克思是错的?——全面批判马列主义的知名著作导读》,其中引用了米塞斯的论文《社会主义国家的经济计算》(Economic Calculation in the Socialist Commonwealth)。米塞斯的这篇论文发表于【1920年】(苏联成立之前)。请注意:苏联是第一个搞【中央计划经济】的国家。在苏联还没有成立的时候,米塞斯就已经在论文中预见了:中央计划经济注定失败(并给出了他的精辟分析)。后来的事实证明他说对了——包括咱们天朝在内,【所有的】中央计划经济,最终都惨淡收场。 ★博弈的类型"博弈的类型"是博弈论的基本概念,先来聊这个。 ◇合作博弈(cooperative game) VS 非合作博弈(non-cooperative game)不论是"合作博弈"or"非合作博弈",在博弈过程中都可能会出现"合作"的现象。差别在于—— 对于"合作博弈",存在某种【外部约束力】,使得"背叛"的行为会受到这种外部约束力的惩罚。 对于"非合作博弈",【没有】上述这种"外部约束力",对"背叛"的惩罚只能依靠博弈过程的其它参与者。 举例:商业活动中有"合同法",就相当于上述所说的【外部约束力】。 通常所说的"博弈"大都指"【非】合作博弈"。大多数博弈论的研究也是针对后者(非合作),俺这篇教程的大部分内容也是针对后者。 ◇同时博弈(simultaneous game) VS 顺序博弈(sequential game)同时博弈(静态博弈) "同时博弈"有时也称作"静态博弈",指的是——博弈的【任何一个】参与者在选择自己的行为之前,并【不】知道其它参与者的行为信息。 举例:"石头/剪刀/布" 顺序博弈(动态博弈) "顺序博弈"有时也称作"动态博弈"。在这类博弈中,参与者的动作有【时间上的先后】,并且后一个执行动作的博弈者可以看到其他博弈者之前的动作,然后根据别人的动作,思考自己的行为。 举例:绝大部分棋牌类游戏都属于这种。 ◇零和博弈(zero-sum game) VS 非零和博弈(non-zero-sum game)零和博弈 "零和博弈"这个名称具有误导性,使得很多人以为各方的收益总和为零。 "零和博弈"指的是——在博弈结束之后,参与各方的利益总和为【常量】(可以是零,也可以是"正值"或"负值")。 举例:大多数棋类游戏属于这种;"石头/剪刀/布"也属于这种。 非零和博弈(变和博弈) "非零和博弈"指的是——在博弈结束之后,参与各方的利益总和为【变量】。所以这类博弈有时候称为【变和博弈】。 对于这类博弈,在某些情况下可能会让参与各方的利益总和【变大】,从而使得各方存在【合作】的可能性。 举例:在"非零和博弈"中,最有名的应该就是"囚徒困境"(Prisoner's Dilemma)了。这个"困境"非常有名,这里就不详细解释啦。不太了解的同学,先看俺加注的维基百科链接。因为后续的讨论中,会多次提及这个模型。 ◇非重复博弈(non-repeated game) VS 重复博弈(repeated game)"非重复博弈"有时也称作"单次博弈";相应的,"重复博弈"也被称作"多次博弈"。 以"囚徒困境"为例。如果困境中的两个嫌疑人只被抓进去一次,那就是"单次博弈";如果被抓进去不止一次,就是"多次博弈"。 "重复博弈"还可以进一步细分为"有限重复博弈"(finite repeated game)与"无限重复博弈"(infinite repeated game)。 这2个术语容易产生歧义。更严谨的说法是: "有限重复博弈"——重复次数【确定】的博弈 "无限重复博弈"——重复次数【不确定】的博弈 ★收益矩阵 VS 决策树◇概述这两个玩意儿都是为了更直观地描述博弈过程,并帮你看清各方的利弊得失。 "收益矩阵"通常用来描述"静态博弈"(同时博弈);由于"动态博弈"(顺序博弈)比较复杂,通常【不】用"收益矩阵"描述。 "决策树"既可以用来描述"静态博弈",也可以用来描述"动态博弈"。 顺便提醒一下: 在某些书籍/文章中,把"收益矩阵"称作"普通形式"(normal-form);把"决策树"称作"扩展形式"(extensive-form)。 ◇收益矩阵(payoff matrix)上一个小节说了:"收益矩阵"通常用来描述【静态博弈】。而且一般是用来描述【双人】的静态博弈。更多人的静态博弈,也可以用"收益矩阵"表述,但画起来会麻烦很多。在本文的后续部分,凡是提及"收益矩阵"都是指"双人静态博弈"。 通常的惯例是把自己这方的策略写在表格【左边】,把对方的策略写在表格【上边】。为了让大伙儿有个直观感受,俺写一个"石头/剪刀/布"的"收益矩阵"。
在上述矩阵中, 1 表示赢;-1 表示输;0 表示平局。◇决策树(decision tree)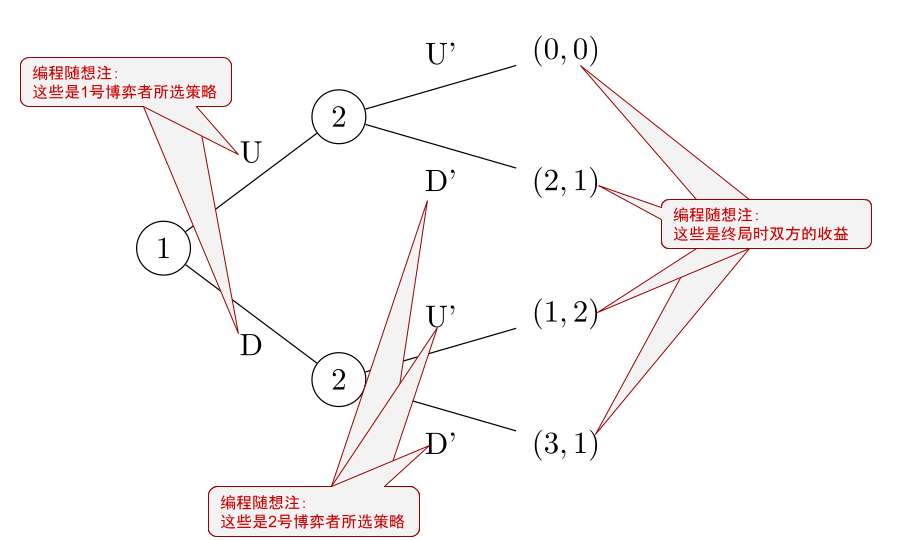 (一个简单决策树的示意图) 上述是一个决策树的示意图,表示一个简单的"双人动态博弈",两个博弈者分别称作 1 & 2;两人的可选策略都只有2个(分别是:U & D)。 1 先执行某个动作,然后 2 再执行对应的动作,然后博弈就结束了。这个树状图有4个叶子节点,表示该博弈最终有4种结局。每个叶子节点的括号中各有2个数字,分别表示两个博弈者在不同终局的收益。 ★策略 & 策略集合◇决策选项(move) VS 策略(strategy)某些资料(比如维基百科)把"move"直译为"移动"。这个译法比较怪。在本文中,俺称之为"决策选项"。 很多人混淆了"策略"与"决策选项"。 以象棋为例,完成一局需要经历很多个步骤。对每个步骤,你都有 N 个决策选项(要走哪个棋子,走到哪)。而"策略"指的是——从第一步到最后一步的所有决策选项的【总和】。你可以把"策略"通俗理解为某种【算法 or 指导思想】,它指导你从第一步走到最后一步。 ◇策略集合(strategy set)所有可能的策略,构成了"策略集合"。 以"石头/剪刀/布"为例,其"策略集合"只包含3个策略。 ◇有限策略集合 VS 无限策略集合有限策略集合 "石头/剪刀/布"就是典型的"有限策略集合"(该集合只有3个元素)。 无限策略集合 为了说明这种集合,举个"分蛋糕博弈"的例子。 所谓的"分蛋糕博弈"很简单——这是双人博弈,其中一人先把蛋糕分为两块(可以随便分),然后另一个人先挑选其中一块。 对于"负责分蛋糕"的人而言,其策略集合是无穷大(纯小数有无穷多个)。 ◇关于"有限/无限"的反直觉很多人凭直觉会认为:具有"无限策略集合"的博弈比"有限策略集合"的博弈更复杂。其实不然! 围棋虽然很复杂,但其"策略集合"依然是有限滴(只不过,要想描述这个集合,需要存储的信息量会超出整个宇宙的承受能力)。 作为对比,"分蛋糕博弈"比"围棋"简单多了(两者的复杂性相差 N 个数量级),但"分蛋糕博弈"反而具有【无限】的策略集合。 ★纯策略 VS 混合策略◇纯策略(pure strategy)在实际博弈时,如果你总是【固定选择】"策略集合"中的某【一个】策略,这种情况称之为"纯策略"。 以"石头/剪刀/布"为例:如果你每次总是出"石头",这就是【纯策略】。 ◇混合策略(mixed strategy)如果你在博弈时,总是【随机选择】"策略集合"中的某【几个】策略,这种情况称之为"混合策略"。 以"石头/剪刀/布"为例:如果你一半概率出"石头"一半概率出"剪刀",这就是【混合策略】。 ◇完全混合策略(totally mixed strategy)如果某个"混合策略"包含了"策略集合"中的【每一个】元素,称之为"完全混合策略"。 上一个小节的举例(一半概率出"石头"一半概率出"剪刀")属于"混合策略",但【不是】"完全混合策略"。 作为对比,如果你1/4概率出"石头",1/4概率出"剪刀",1/2概率出"布"——这就是"完全混合策略"。 ★支配策略(优势策略)◇策略之间的【支配性】假设你有两个策略 A & B。如果在【任何】情况下,A 都比 B 更优,称作"A 支配 B"(A dominates B)或者"B 被 A 支配"(B is dominated by A)。 ◇支配策略(dominant strategy)"支配策略"又称"优势策略"。如果某个策略能够支配【所有】其它策略,那么它就是"支配策略/优势策略"。 通俗地说,不论你的对手采用何种策略,你的"支配策略"总是比你的其它策略有更好的结果。 在后面的某个小节,俺会举个很简单的例子,帮你理解"支配策略"这个概念。 ◇强支配策略(strictly dominant strategy) VS 弱支配策略(weakly dominant strategy)有时候会把"支配策略"进一步细分为"强支配"&"弱支配"。 对于前者,它在任何情况下都比其它策略更好;对于后者,它在某些情况下比其它策略更好,某些情况下与其它策略一样好。 ◇支配策略 VS 制胜策略(winning strategy)有些人会把"支配策略"与"制胜策略"搞混淆。 "制胜策略"也称"必胜策略",它通常只用于"零和博弈",指的是——只要你采用这个策略(不论对方如何应对),你总是赢。 "制胜策略"肯定是"支配策略"(最起码是"弱支配策略");但"支配策略"不一定是"制胜策略"。 ◇实例:(二战中)新几内亚的航路作战这是一个很经典的博弈论案例,很多博弈论的科普读物都引用了此案例。比如俺分享的那本《纳什均衡与博弈论——纳什博弈论及对自然法则的研究》就包含了这个案例。 话说太平洋战场上,美日双方对新几内亚岛展开争夺战。美方通过截获的情报得知日方有一支补给船队要开往该岛。日军补给船队有两条路线可走(北线 or 南线),两条路线都耗时3天。在南线,这3天都是晴天;在北线有2天是晴天,1天是阴雨(阴雨天会影响美军轰炸)。 美方空军将领手头只有一个飞行队,需要决策:把这个飞行队派到哪一边执行轰炸任务?如果押宝的方向错误,重新部署又会浪费掉1天时间。 对这个博弈过程,美方的收益矩阵参见下述表格。表格中的数字表示"可用来轰炸的天数"(对美军而言,这个数字越大越好)。
第2个表格补充了日方的收益(以逗号分隔)。由于日方是遭受轰炸,其收益以"负数"表示。 从日方的角度(表格的【纵向】角度)来看,走北线是其【支配策略】——不论美方如何选择,日方走北线的收益都不比南线差。对应到刚才介绍的概念,日方的这个"支配策略"属于"弱支配策略"。 知道日军必定走北线之后,美军就很容易选定自己的策略了。 ◇如何发现"支配策略"?一个比较简单的做法是:逐步删除【被】支配的策略(洋文叫做"Iterated Elimination of Strictly Dominated Strategies",简称 IESDS)。 下面这一系列示意图,演示了逐步删除的过程。最后剩下的那个单元格,也就是该博弈的"纳什均衡点"(关于"纳什均衡",后面有个章节会专门细聊)。    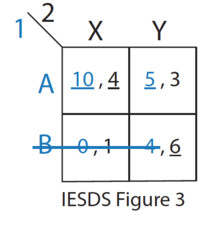 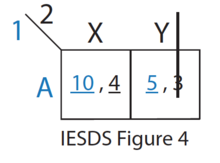 ◇"支配策略"的【罕见性】一般来说,只有极其简单的博弈才存在"支配策略"。只要博弈再稍微复杂那么一丁点,"支配策略"可能就不存在了。 举个栗子:哪怕像"石头/剪刀/布"这么简单的游戏,就已经不存在"支配策略"了。 ◇"支配策略"的【乏味性】当某个博弈存在"支配策略",这个博弈通常就显得索然无味。反过来想,你就能理解——为啥绝大部分棋牌类游戏都【没有】"支配策略"。 ★最小最大定理◇概述这个玩意儿洋文叫做"Minimax",比较绕口的陈述是:最小化最大损失。更通俗的表述是:在最坏情况下最小化损失。 该定理及算法最早由冯·诺依曼在《博弈论与经济行为》一书中提出。本文开头部分介绍过——此书是博弈论的奠基性著作。 ◇举例:静态博弈假设你是 A(你有三个策略:A1、A2、A3),你的对手是 B(也有三个策略:B1、B2、B3)。 以下是针对 A(你)的收益矩阵:
针对上述收益矩阵,基于 Minimax 算法,你应该选择 A2 策略——此时你的最坏情况是 -1。◇举例:动态博弈——切蛋糕博弈前面章节已经简单介绍过"分蛋糕博弈"。这是一个非常简单的动态博弈(步骤很少)。 当双方都是足够理性,选蛋糕的人肯定会选大的那块。切蛋糕的人基于"最小最大原则",应该在最坏情况下最小化自己的损失,所以他/她应该把蛋糕切成同等大小。 ◇思考题给那些爱琢磨的读者留一个思考题 :) "分蛋糕博弈"的精妙之处在于"切的人后拿,不切的人先拿"。这就完美地解决【双人】分蛋糕的公平问题。 那么,如果是更复杂的【三人】分蛋糕,是否存在某种类似的机制,也可以完美地解决公平问题捏? 更一般的情况,对于【N 人】分蛋糕(N ≥ 3),是否有某种类似的机制捏? 对于善用搜索引擎的同学,很容易就可以在网上找到这个问题的答案。但俺建议你在上网搜索之前,先自己琢磨一下(就当这是个锻炼脑力的机会) ★反向归纳法◇概念该方法洋文称之为"backward induction"。其精髓是【正向展望,反向推理】。 在俺分享的那本《策略思维——商界、政界及日常生活中的策略竞争》中,多次提及了这个精髓。具体如何做捏?俺先稍微描述一下,然后再用具体案例加深大伙儿的印象。 首先,你需要思考自己的每个决策,以及对方在应对你的决策时,会采用何种决策(这个思维过程类似于【决策树的展开】) 这个展开过程要一直推演到【最后一步】(也就是决策树的叶子节点)。此时你就可以看清双方在最后一步各自的最优选择;然后再反向回推到第一步。 ◇局限性当你要用"反向归纳"进行展望与推理,前提是——你要获得充分的信息;或者说,如果某个博弈者所知的信息不够充分,就【无法】运用该方法。 在本文后续的某个章节,俺会专门谈"博弈中的【信息】因素"。 ◇重复博弈中的"囚徒困境"前面提到的"囚徒困境"属于【单次】静态博弈。如果把这个局面改为【多次】,并且两个囚徒足够理性且相互认识,并且两人也都知道自己处于【多次】博弈的场景,那么就有可能达成合作。 无限重复博弈(次数不确定) 在这个博弈场景中,由于两个囚徒都知道未来还会有多次类似的博弈局面,所以他们在第一次被抓的时候,就会选择合作(双方都抵赖),并且未来也会每次都选择合作。 他们之所以选择合作,是为了给将来博弈中的合作建立基础。 有限重复博弈(次数确定) 假设次数确定为【10次】。这种情况下,是否还可能达成合作捏?很多同学凭直觉认为:还是可以合作。其实不然! 对于有限重复的情形,就需要用到本章节的"反向归纳法"了。 先分析【最后一次】(第10次)博弈的情形。因为不再有后续的博弈,此时的局面等价于【单次】博弈(单次囚徒困境)——也就是说,双方会选择背叛。 如果两人都足够理性,当他们在进行第9次博弈的时候,就应该能想到——下一次博弈是最后一次,不会有合作。既然如此,那么本次博弈,当然也没必要合作了(请注意:合作是为了下次能继续合作) 上述反推可以一直持续到第一次。所以,如果双方都足够理性,在第一次就会选择互相背叛。 ◇海盗博弈(海盗分金问题)上述例子太简单啦,再来个稍微复杂的例子。 博弈场景描述 5个海盗抢了100个金币,讨论如何分赃。 这5个海盗有等级高低(不妨假设 A>B>C>D>E)。先由等级最高的海盗提出分赃方案,然后投票。如果半数以上(含半数)同意,就按这个方案分,游戏结束;如果同意的不到半数,把提出方案的海盗扔进海里喂鲨鱼,然后由次一等级的海盗提出新的方案;以此类推。 每个海盗的特点是:足够理性(追求个人利益最大化)并且知道别人也足够理性;足够残忍(在个人利益等同的情况下,倾向于把更多同伴扔进海里)。 现在,请你思考一下最终的结局(需要用到本章节所说的"反向归纳法")。 给 你 一 柱 香 的 时 间 思 考 这 个 问 题 , 先 别 急 着 往 下 翻 页 :) 博弈策略分析 为了进行反向推理,假设最后只剩下2个海盗(D & E)。此时的投票肯定过半(D 肯定投票赞同自己的方案)。在这种局面下,D 可以采用最极端的方案——自己全拿100个金币,E 则一个也拿不到。 现在回推一步。当只剩下3个海盗(C、D、E),由 C 提出方案。他只需要分1个金币给 E,E 就会投票支持(否则的话,等到由 D 来提方案,E 啥也拿不到)。所以在 C 的方案中,他自己拿99个金币,E 拿1个金币。 再往前一步。只剩下4个海盗(B、C、D、E),B 提方案,他当然也能想到刚才那些推理。他只需给 D 1个金币,D 就会支持他(如果等到 C 来提方案,D 啥也拿不到)。所以 B 提出的方案是 B:99,C:0,D:1,E:0,同样能得到半数支持。基于上述分析,再看 A 的方案,就很显然了—— A:98,B:0,C:1,D:0,E:1有些同学可能会觉得:A 还可以提出另一个等价方案 A:98,B:0,C:0,D:1,E:1(把 C & D 交换)其实这个方案【不】等价。如果是后面这个方案,D 会投反对票,于是 A 去喂鲨鱼,由 B 来提方案,D 还是可以拿到1个金币。虽然两种方案,D 都是拿1个金币。但基于规则中提到的【残忍性】,D 会对 A 的方案投反对票。 海盗分金的推广 如果你凭直觉认为:总是最先提出方案的海盗占最大利益,那你就犯了直觉谬误啦。 这个博弈游戏还可以推广到更多海盗。当海盗数量达到某个临界点之后,第一个提出方案的海盗必死无疑(必定被丢进海里喂鲨鱼)。 更详细的介绍,可以参见维基百科的"这个链接"。 ★纳什均衡前面喷了好多口水,终于要聊到大名鼎鼎的"纳什均衡"(Nash equilibrium)啦。 美国数学家纳什在1951年发表了一篇小论文(篇幅很短),名叫《非合作博弈》,洋文标题是《Non-Cooperative Games》,其中提出了"纳什均衡"的概念并给出了相应的数学证明(该证明基于"不动点定理")。  (约翰·福布斯·纳什) ◇概念所谓的"纳什均衡",通俗地说是指——在多人的"非合作博弈"中,如果每个博弈者都无法【单方面】改善自己的境地,此时的局面称作"纳什均衡"。 冯·诺伊曼已经在《博弈论与经济行为》一书中证明了:零和博弈必定存在这样的均衡点。 纳什的贡献在于——他从"零和博弈"推广到"非零和博弈",并证明了:这样的均衡点依然存在。 这里有几个定语需要注意: 其一,"纳什均衡"的前提是【非合作博弈】。不要望文生义,把"非合作博弈"误解为"没有合作的博弈"。请参见本文开头章节对"博弈类型"的解释。 其二,【单方面】指的是——在其他博弈者都没有改变策略的情况下,自己改变策略。 ◇"纳什均衡"的【稳定性】当博弈的局面处于"纳什均衡",此时的系统是【稳定】滴——如果每个博弈者都足够理性,他们都【不愿意】主动改变当前的策略。 ◇实例:囚徒困境几乎每一个讲"纳什均衡"的资料(书/文章)都会拿"囚徒困境"来举例,俺也不能免俗 :( 以下是"囚徒困境"的收益矩阵(被判刑的年数以负数表示,零表示立即释放):
基于上述矩阵,"双方都坦白"的局面是"纳什均衡点"(表格中着色的格子)——在这个均衡局面下,任何一个囚犯【单方面】改变策略,只会让自己更不利。 作为对比,"双方都抵赖"虽然是双赢的局面,但这个局面是【不】稳定滴。因为在这个局面下,任何一个囚犯都有动机去改变策略,从而让自己的获益更多。 ◇实例:石头/剪刀/布对这个游戏,有一个稳定的【混合策略】——其中每个策略各占1/3的权重(以相等的概率随机使用这3个策略)。 当双方都采用这个混合策略,此时博弈处于"纳什均衡"。 对于"石头/剪刀/布"而言,这是【唯一】的"纳什均衡点"。不信的话,你可以试着考虑其它各种局面,会发现其它的局面都不稳定,(只要双方足够理性)最终都会演化到上述的均衡点。 ◇对"纳什均衡"的【误解】误解1:把"纳什均衡"误解为"各方利益总和最大化"。 实际情况是:"纳什均衡"与利益最大化没啥关系。甚至可能出现相反的情况——当局面处于"纳什均衡"时,对博弈的各方都不利。 典型的例子参见"囚徒困境"——均衡的时候,反而是【双输】的局面。 误解2:认为"纳什均衡点"是唯一的。 实际情况是:对某些博弈,可以有【多个】"纳什均衡点"(下面聊"三党博弈"会提及) ◇"纳什均衡"的【局限性】局限性1 纳什的证明是【非建设性】滴。也就是说,他只是证明了这个均衡点必定存在,但【没有】给出"如何找到均衡点"的方法论。 那么,如何找到均衡点捏? 进入21世纪之后,数学家已经证明:即使对于某些比较简单的博弈,找到纳什均衡点所消耗的计算量也会超出整个宇宙的承受力。 从这些数学家的成果中,你会再次感受到"复杂系统"的魅力与挑战——即使是一些看似简单的系统,其【复杂性】也已经远远超出人们的想象。以下这篇博文,有助于你更全面地理解这点: 《"政治体制"与"系统健壮性"——基于"复杂性科学"的思考》 局限性2 对于任何一个稍微复杂点的博弈,要想达到"纳什均衡点",需要依赖于非常非常多的约束条件;在现实生活中,不太可能达到。 上个月(2020年10月)俺写了一篇博文谈美国政党简史。当时有读者在那篇博文留言并问道:为啥"多党制"总是演变为"两党制"?然后俺写了一条长篇留言,从【博弈论】的角度进行分析。 在那条留言的末尾部分,俺聊了"三党博弈"如何才能出现均衡。"三党博弈"确实有可能达成均衡(而且均衡点还不止一个),但每一个均衡点要依赖的约束条件太多了。这么多约束条件同时满足,概率本来就很低(趋向于零)。即使真的出现了,这种局面也很容易被干扰(只要某个约束条件不再满足,局面就被破坏了)。作为对比,"两党博弈"就更容易演变到"纳什均衡点",也更容易长期维持。 如果连"三个实体的博弈"都如此难达成均衡。你可以粗略想象一下:在更复杂的博弈中,达成"纳什均衡"的可行性有多么低。 ★博弈中的【信息】因素聊完"均衡",重要的概念基本上讲差不多了。下面开始聊博弈中涉及的一些因素,首先是"信息"因素。 ◇"perfect information" VS "imperfect information"这两个概念通常针对"顺序博弈"(动态博弈)而言。 在博弈过程中,如果每个参与者在做每个决策时,都能知道已经发生的每个事件的信息,称作"perfect information";反之则是"imperfect information"。 大部分棋类游戏(围棋、象棋、跳棋...)属于前者;某些军棋游戏(只能看到己方的棋子)属于后者;大部分扑克游戏(比如:桥牌、拱猪...)属于后者。 ◇"complete information" VS "incomplete information"在博弈论的讨论中,很多人混淆了"perfect information"与"complete information"。 "complete VS incomplete"的讨论主要针对【博弈者】。如果每个博弈者的特征都是公开的(每个人都知道其他人的特征),则称为"complete";反之是"incomplete"。 "博弈者的特征"是啥捏?通俗地说包括:博弈目标、效用函数(为达到不同级别的目标愿意付出多大代价)、等等。 举例: 几乎有所有的【棋牌类游戏】都属于"complete information"——双方的目标是公开且固定的(比如象棋的目标是干掉对方的王),而且也不用考虑"效用函数"之类的概念。 【拍卖】则属于"incomplete information"——有些人是真的买家,有些人只是为了抬价;即使是真正的买家,各自的底线也不公开。 ◇对翻译的吐槽前面2个小节谈"perfect information"&"complete information",俺为啥都用洋文,而不用中文? 就是因为这2个玩意儿的中文翻译没有统一。有些博弈论的资料,把"perfect information"翻译成"完全信息";另一些资料则把"complete information"翻译成"完全信息"。真是坑爹啊!再加上这两个概念本来就很容易搞混(如前所述),所以俺只好全用洋文来称呼之。 今后你阅读某些博弈论相关的书籍或文章,一旦看到有中文的"完全信息",先得搞清楚它想表达的,到底是"perfect information"还是"complete information"。 ◇贝叶斯博弈(Bayesian game)& 贝叶斯纳什均衡(Bayesian Nash equilibrium)对于"incomplete information"的博弈,由于每个博弈者无法完全掌握其它博弈者的特征。对这类博弈,需要引入【贝叶斯定理】(Bayes' rule)进行概率分析,从而猜测其它对手的特征。所以这类博弈也称作"贝叶斯博弈"。 "贝叶斯定理"是概率论的重要工具。要对它展开讨论,至少又是一个长篇博文。暂且打住。 对于"贝叶斯博弈",其纳什均衡称之为"贝叶斯纳什均衡",洋文简称 BNE(Bayesian Nash equilibrium)。 ◇实例分析:翻墙工具 VS GFW俺写翻墙教程已经有十多年的历史了(最早的一篇写于2009年),平时也经常有读者在博客留言,询问相关话题。本小节就拿翻墙来举例。 下面这个例子,俺曾经在博客评论区与某读者交流过。考虑到大部分读者平时不逛评论区,今天把这个案例拿出来聊聊。 1. 翻墙工具的两大类 根据【服务器】的差异,大部分翻墙工具可以分为两类:使用【公共的】翻墙服务器 or 使用【自建的】翻墙服务器。 2. "公共服务器"的翻墙方式 这类翻墙工具至少包括:VPNgate、赛风、蓝灯、自由门、无界... 对这类翻墙工具,GFW 至少有如下两招来对付: 其一,在国际出口识别翻墙工具的通讯协议,如果发现某个流量被用于翻墙,直接阻断之。 其二,GFW 的研究人员可以去翻墙工具的官网下载翻墙客户端,然后在自己的环境(沙箱环境)运行这个客户端,并分析它会连接哪些公共服务器。最后把收集到的服务器 IP 地址加入"IP 黑名单"。 前面这招叫做【协议识别】,后面这招是【沙箱分析】。 3. "自建服务器"的翻墙方式 这类翻墙工具至少包括:ShadowSocks 及其衍生品... 由于服务器是翻墙网民【私有】的(比如私人购买的 VPS)。首次运行翻墙客户端之后,通常还需要再配置服务器的 IP 地址(这个信息对 GFW 是【保密】滴)。 在这种情况下,GFW【无法】使用"沙箱分析"去收集"翻墙服务器的 IP",而只能动态识别翻墙协议。 4. GFW 的封锁成本 GFW 要想封锁翻墙工具,比较常见的两招是:"协议识别"&"IP 黑名单"。 (注:为了对付自建服务器的翻墙工具,GFW 近些年开始引入【主动探测】,但这招用得不算多。用得最多的应该还是上述两招) 至于 GFW 的其它招数(比如:域名污染、关键字过滤)是用来对付普通上网,对翻墙工具基本无效。 在 GFW 对付翻墙工具的这2招里,"协议识别"会消耗很多的 CPU 运算量,导致封锁成本提高;(相对而言)"IP 黑名单"的成本要低得多。 (注:如果只是对单个流量进行协议分析,CPU 的运算量不大;但 GFW 部署在【国际出口】,需要并发处理成千上万的流量,这时候 CPU 的压力就体现出来了) 5. 小结 综上所述,当 GFW 碰到那些使用【公共服务器】的翻墙工具,更接近于【单向的】"perfect info"博弈(翻墙工具对于 GFW 而言是"perfect info",而 GFW 对于翻墙工具而言是"imperfect info") 反之,当它碰到那些【自建服务器】的翻墙工具,更接近于"imperfect info"博弈。 ★博弈中的【心理】因素◇换位思考在博弈所涉及的诸多心理因素中,俺首先要聊的是【换位思考】。 前面聊的很多博弈相关技能(比如:最小最大原则、反向归纳法),都依赖于"换位思考"这个能力——你需要站在【对手】的角度进行思考,才能看清局面,从而更好地选择自己的策略。 "换位思考"的好处不仅仅体现在博弈中,还体现在其它很多方面。比如说:俺在博客中不止一次地强调【批判性思维】的重要性,也不止一次地介绍过"批判性思维"分两大类:【弱】批判思维 & 【强】批判思维。后者比前者更重要。一般来说,那些"换位思考"能力越强的人,也越善于进行【强】批判思维。 既然"换位思考"如此重要,某些同学肯定会问:如何才能提升【换位思考】的能力捏? 方法有很多种。其中一个方法,俺在如下博文已经介绍过。 《如何【系统性学习】——从"媒介形态"聊到"DIKW 模型"》 另一个提升【换位思考】能力的方法是——通过某些复杂的博弈游戏,进行练习。 在本博客的长期读者中,有些人知道俺是个围棋爱好者(当年 AlphaGo 横扫人类冠军的时候,还专门发过2篇博文)。俺会利用下围棋的机会,强迫自己更多地进行换位思考。 写到这里,顺便聊聊围棋的几个特点: 1. 节奏慢 只有那些慢节奏的博弈,才可能深度思考;与之对比,电脑上的即时战略游戏,节奏太快了。 2. 复杂性 游戏本身足够复杂,才可能深度思考。 从"决策树复杂度"而言,围棋远远超越所有棋牌类游戏。 3. 换位思考 你既要思考如何攻击对方,也要思考对方如何攻击你。 为了思考"对方如何攻击你",你就要站在对方的角度思考自己的布局,并尝试找出【自己】的弱点。 4. 把握平衡 要想下得好,你需要把握各种平衡,比如:速度与厚味的平衡、大场与急所的平衡...... 顺便说一下:"速度与厚味的平衡"跟这篇博文的某个核心观点(系统的均衡性)是相通滴。 5. 从简单到复杂 大部分棋类游戏(国际象棋、中国象棋、西洋跳棋、军棋......)都是越到后面,局势就越简单明朗;扑克类游戏也是如此。 但围棋则完全不同。 6. 全局性(全局耦合性) 大部分棋类游戏,要么是"局部性"的(比如五子棋),要么是"全局弱耦合"(比如国际象棋);而围棋属于"全局强耦合"。 围棋的这个特点,使得棋手要建立很好的【大局观】(完全不懂围棋的同学,很难体会此处所说的"大局观") ◇早期经济学的"理性人假设"及其谬误在"博弈论"诞生【之前】,微观经济学在进行数学建模的时候,通常都会引入一个"理性人假设"——假定市场的行为主体(公司 or 个人)是充分理性滴(此处的"充分理性"还隐含着"掌握充分的信息")。 为啥一定要引入这个假设捏?是为了数学建模的需要(否则没法建模)。但这个假设其实非常扯蛋—— 在博文和评论区的交流中,俺多次强调了【平庸的大多数】。对任何一个国家(哪怕是成熟的民主国家),大多数人都很平庸(他们的共同点之一是非常【不】理性)。充分理性(并且掌握了充分信息)的个人,就算有,那也绝对是凤毛麟角。而"理性人假设"竟然设定市场的行为主体全都是充分理性的。这不是睁着眼睛说瞎话嘛? 有了博弈论之后,这个非常扯蛋的"理性人假设"就可以丢到垃圾桶里了 :) 为了帮大伙儿理解,俺用两种不同的理论来解释同一个现象。 比如说,市场上存活的大部分公司,他们生产的商品都是能满足市场需求滴。 旧的经济学理论(理性人的解释)会说——所有公司的老板都充分理性,也掌握了充分的信息,知道应该生产何种商品,才能满足市场需求。 新的经济学理论(博弈论的解释)会说——公司的老板既有聪明的,也有傻逼的。傻逼公司生产的商品没人要,自然会亏损并倒闭。随着时间的推移,经过【自然选择】,活下来的公司当然是那些聪明的(至少不是太笨的)。 题外话:幸存者偏见 早期的经济学家,为啥会想出扯蛋的"理性人假设"捏?其中一个重要原因是【幸存者偏见】。 因为这个思维谬误是如此普遍(且影响深远),俺为这个主题专门写过两篇博文: 《思维的误区:幸存者偏见——顺便推荐巴菲特最著名的演讲》 《思维的误区:忽视沉默的大多数》 ◇装疯策略前一个小节谈了"理性人假设"及其谬误。这个谬误是把"不理性的主体"误当作"理性的主体"。 本小节再来说一个相反的情况——"理性的博弈者"把自己伪装成"非理性的博弈者",这么干可以获得某种【虚张声势】的唬人效果。对这种手法,俺称之为"装疯策略" :) 2017年的时候,朝鲜半岛的【核危机】升级。由于这事儿发生在不久之前,大伙儿应该都有印象吧。 当时很多读者问俺对这场危机的看法,于是俺在2017年写了两篇博文,分别谈"北朝鲜 & 美国"的博弈策略(如下)。当年北朝鲜的金三胖,采用的就是这类"装疯策略"。 《聊聊朝鲜半岛核问题——北朝鲜博弈策略分析》 《聊聊朝鲜半岛核问题——美国博弈策略分析》 ★"博弈论"对其它领域的影响在本文的末尾,稍微聊一下:博弈论对其它领域/学科的影响。 ◇对【经济学】的影响谈"博弈论"的影响,当然首先要谈它对【经济学】的影响。博弈论的问世堪称"经济学在20世纪最重要的革命"。 在前面的某个小节,俺已经提到:有了博弈论,就不再需要那个扯蛋的"理性人假设"了。这是"博弈论"诞生后对微观经济的重大影响。 除了这个影响,还有很多其它的影响。比如说:(博弈论诞生前)传统的微观经济学以"供给/需求"来建立【价格】的数学模型。这个模型只考虑了"供应量/需求量"的变化对价格的影响,而完全【不】考虑供给双方的【力量对比】。 【力量对比】是啥意思捏?如果供给双方中,一方变得强势或另一方变得弱势。即使供应量与需求量都维持不变,价格也会发生变动(朝着对强势方有利的方向移动)。 为了帮大伙儿理解上述这句话,拿咱们天朝臭名昭著的【996工作制】来现身说法。 咱们天朝【没有】真正意义上的工会;各个城市的【官方工会】都是替党说话,而不是替工人(白领、蓝领)说话。在工会缺位的情况下,资方自然变得更强势,而劳方变得更弱势。【996工作制】就是在这个大背景下发展起来滴。通过变相延长工作时间,也就相当于变相压低了劳动力的价格(请注意,劳动力本身也是一种商品)。 实际情况不仅于此。因为996工作制已经开始普及——今年(2020)深圳开始搞相关的试点,企图把这种工作制【合法化】。当这种工作制逐渐普及之后,会在人力资源市场产生某种【正反馈】,从而导致某种更糟糕的后果(对资方而言则是更美好的后果)。相关的分析参见去年(2019)的博文,其中有一个章节是 ★"996工作制"如何影响天朝的人力资源市场? 《"996工作制"只不过是【劫贫济富】的缩影——"马云奇葩言论"随想》 ◇对【军事&外交】的影响"博弈论"当然也会深刻影响军事和外交领域。尤其是在如今这个"战略核武器"的时代,博弈论尤其显得重要。 关于这个主题,俺在今年(2020)写过一篇《聊聊"核战略的博弈模型"与"中美新冷战"》,这里就不展开了。 ◇对【生物学】的影响生物学有很多分支,受博弈论影响最大的分支估计是"演化生物学"(也就是俗称的"进化论")。 借助博弈论的研究成果,"演化生物学家"可以更好地建立物种演化的数学模型。举个栗子:上世纪70年代发展起来的"演化稳定策略"(Evolutionarily Stable Strategy,简称 ESS)。这个理论可以更好地解释物种的自然选择。 俺的网盘上分享的那本《纳什均衡与博弈论——纳什博弈论及对自然法则的研究》,其第4章专门聊"博弈论如何应用到演化论"。 顺便说一下:"进化论"这个中文翻译不太恰当,会让人产生一种(下意识的)错觉——似乎进化带有某种方向性&目的性。为了消除这种错觉,如今越来越多的科普读物开始改用"演化论"这个中文翻译。 ★结尾由于本文定位于【基础性扫盲】,只能蜻蜓点水,简单聊聊。这里面的很多话题,假如要深入细谈,可以再写出好几篇博文。 如果你对这方面感兴趣,可以在博客评论区进行反馈。很多时候,俺会根据读者需求,适当调整"写博文的权重"。 另外,也感谢很多热心读者,长期与俺在评论区交流。本文中提到的好几个案例,都是前些年与读者交流时聊到的。 俺博客上,和本文相关的帖子(需翻墙): 《"政治体制"与"系统健壮性"——基于"复杂性科学"的思考》 《聊聊"核战略的博弈模型"与"中美新冷战"》 《聊聊朝鲜半岛核问题——北朝鲜博弈策略分析》 《聊聊朝鲜半岛核问题——美国博弈策略分析》 《"996工作制"只不过是【劫贫济富】的缩影——"马云奇葩言论"随想》 《美国政党简史(上)——从"邦联时期"到"南北战争前"》 《为什么马克思是错的?——全面批判马列主义的知名著作导读》 《思维的误区:幸存者偏见——顺便推荐巴菲特最著名的演讲》 《思维的误区:忽视沉默的大多数》     | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| You are subscribed to email updates from 编程随想的博客. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |